|
A Object-Oriented Implementation of a Chemical Waste Consolidation Expert System
Return to front page 1. Background and Rationale 2. Interface Design
3. System Design
4. Evaluation and Results 5. Future Work 6. Conclusions Bibliography and References Appendix A. Example Drum Report Appendix B. Chemical Compatibility Testing Data |
3.2.The Waste Consolidation System Design Overview
The software is modularized into five files corresponding to the three classes, one structure definition and one C++ file. The C++ file drives the three library classes, which are built of structures specific to the library. The class files are titled ChemBook, BottleBook andDrumBook, and they operate the chemical, bottle and drum libraries respectively. Each library is composed of an array of specific structures for storing the library information. They are the data representation of a chemical, transport container and storage container. Figure 3.1 shows the original proposed library object structures. 
Figure 3.1. Original Waste Consolidation System Object Designs
The main body of the program is a chemical compatibility classification system that processes each TransportData object using the knowledge base of the ChemBook chemical structures and linked lists in succession to determine the compatibility and composite waste type. The “rules” are composed of one linked list of chemical name and chemical type designators, with a separate list of chemical name, incompatibles and reactivity index. By matching the two linked lists, the module can find that dichloromethane is a halogenated solvent and halogenated solvents are incompatible with oxidizers which nitric acid is. The process is illustrated in Figure 3.2. 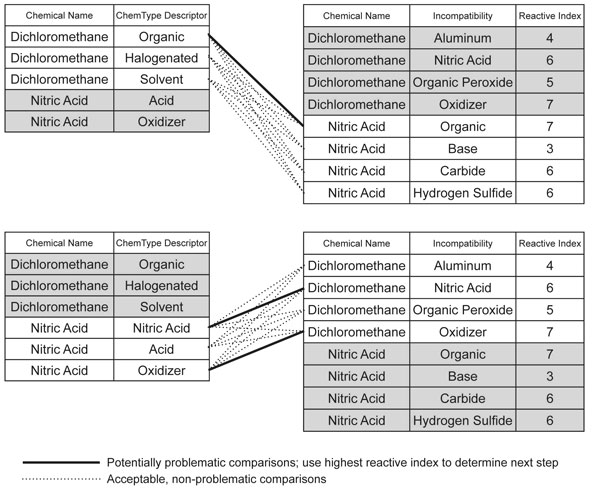
Figure 3.2. Rule Comparison for Nitric Acid and Dichloromethane
The linked list also has a numerical designator of the level of incompatibility. The incompatibility level of the dichloromethane-nitric acid mixture is 7 representing this is dangerous in very low concentrations of the two reactants. Of the two methods of reasoning in expert systems, this is called “forward chaining” [Wikipedia 2005]. The chemical compatibility classification system successively processes each ChemBook object that corresponds to a chemical in that container. Each chemical object modifies the stored TransportData information based upon relative amounts of that chemical. It uses volumetric and density data of each ingredient to determine mass of that ingredient and number of gram-moles. The volume is multiplied with the NFPA numbers to generate volume-weighted accumulations of all the chemicals in the bottle. Division by the total volume of the bottle yields an NFPA number representing the mixture. This is effective for flammability and reactivity but not so for NFPA Health numbers. If the chemical is an acid or base, the number of moles is used to keep a running accumulator of the acidity of the container. There is an accumulator for organics, oxidizers and corrosives that modify the TransportData information. These modifications permit the waste container to be classified based upon flammability, acidity, reactivity and other factors such as organic, oxidizer and corrosive volume fraction. The process for the initial classification of a TransportData is shown in Figure 3.3. 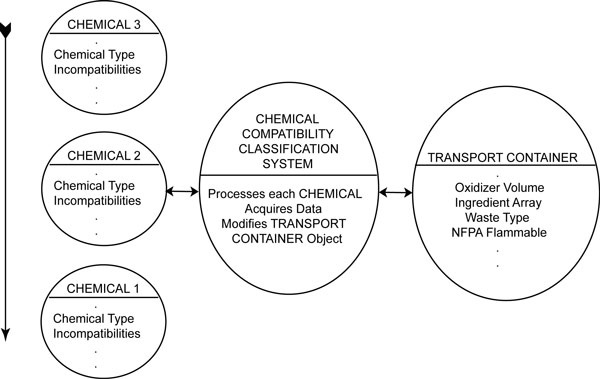
Figure 3.3. Initial Classification of TransportData Container
Each class has routines to insert, view, modify and delete these TransportData structures from the library. In addition, the data structures are used to form a linked list. The bottle ingredients form another linked list; together, they perform specific functions required by the BottleBooklibrary, as shown in Figure 3.4. 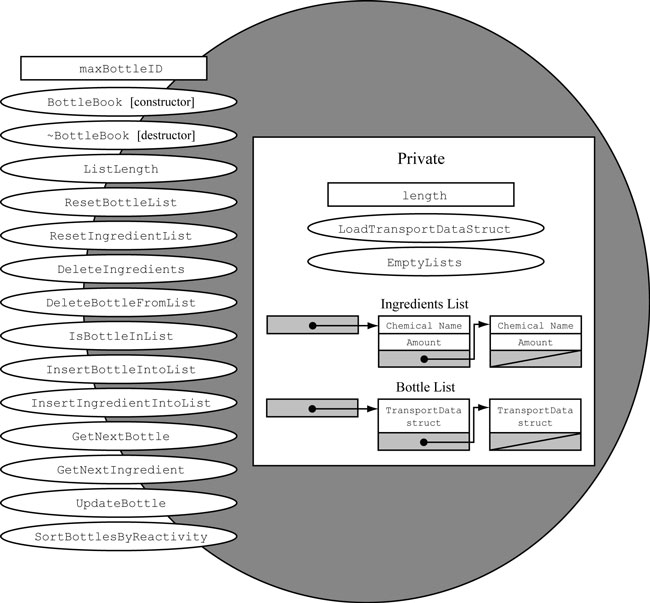
Figure 3.4. Design of the BottleBook Class
As a separate class, each library is a logical division of the software and helps to modularize the design. In turn, this helps with troubleshooting, problem isolation and data abstraction, but these benefits come with a price. Because of encapsulation, the library classes can not directly access the global instance of the other libraries. All processes interacting with more than one library require a routine to be performed in the C++ program. This forces the C++ program to clone the information from one library, manipulate it with the mirrored information from another library, and reinsert the information back into the original library. |
